Tesseract (software)
Tras diez años sin ningún desarrollo, fue liberado como código abierto en el año 2005 por Hewlett-Packard y la Universidad de Nevada, Las Vegas.
En 1995, Tesseract era uno de los tres mejores motores OCR en cuanto a precisión, además está disponible para Linux, Windows y Mac OS X, sin embargo, sólo ha sido probado por los desarrolladores en Windows y Ubuntu.
En estas primeras versiones no se incluía análisis de patrones, y por tanto, las imágenes con múltiples columnas o anotaciones producían resultados ilegibles.
Desde la versión 3, Tesseract soporta el formato en el texto y el análisis del patrón de la página.
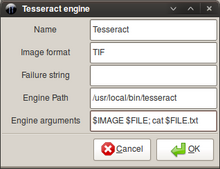
[6] Aunque Tesseract no se distribuye con una interfaz gráfica, hay varios proyectos independientes que le proporcionan una.